
peewee 操作详解–增删改查
[TOC]
本文中代码样例所使用的 Person 模型如下:
class Person(Model):
Name = CharField()
Age = IntegerField()
Birthday = DateTimeField()
Remarks = CharField(null=True)
一、新增
1、create
Model.create 向数据库中插入一条记录,并返回一个新的实例。
p = Person.create(Name='张三', Age=30, Birthday=date(1990, 1, 1))
2、save
save(force_insert=False, only=None)
# force_insert:是否强制插入
# only(list):需要持久化的字段,当提供此参数时,只有提供的字段被持久化。
p1 = Person(Name='王五', Age=50, Birthday=date(1970, 1, 1))
p1.save()
3、insert
insert 只插入数据而不创建模型实例,返回新行的主键。
Person.insert(Name='李四', Age=40, Birthday=date(1980, 1, 1)).execute()
4、insert_many
insert_many(rows, fields=None)
# rows:元组或字典列表,要插入的数据
# fields(list):需要插入的字段名列表。
说明:
1、当 rows 传递的是字典列表时,fields 是不需要传的,如果传了,那么,rows 中的字段在字典中必须存在,否则报错。如果没有传递 fields 参数,那么默认取所有字典的交集作为插入字段。这个也好理解,比如一个字典的键是a、b、c,一个是 b、c、d,那么就取 b、c 作为需要插入的字段。peewee 不会为缺失的字段做默认处理。
2、当 rows 传递的是元组列表时,必须指定 fields,并且 fields 中字段名的顺序跟元组一致。元组中值的数量必须大于等于 fields 中字段的数量,一般建议是保持一致。
Person.insert_many(
[('张三', 30, date(1990, 1, 1)),
('李四', 40, date(1980, 1, 1)),
('王五', 50, date(1970, 1, 1))],
['Name', 'Age', 'Birthday']
).execute()
Person.insert_many([
{'Name': '张三', 'Age': 30, 'Birthday': date(1990, 1, 1)},
{'Name': '李四', 'Age': 40, 'Birthday': date(1980, 1, 1)},
{'Name': '王五', 'Age': 50, 'Birthday': date(1970, 1, 1)}
]
).execute()
对于批量操作,应该放在事务中执行:
with db.atomic():
Person.insert_many(data, fields=fields).execute()
在使用批量插入时,如果是 SQLite,SQLite3 版本必须为 3.7.11.0 或更高版本才能利用批量插入API。此外,默认情况下,SQLite 将 SQL 查询中的绑定变量数限制为 999。
SQLite 中,当批量插入的行数超过 999 时,就需要使用循环来将数据批量分组:
with db.atomic():
for idx in range(0, len(data), 100):
Person.insert_many(data[idx: idx+100], fields=fields).execute()
Peewee 中带有一个分块辅助函数 chunked(),使用它可以有效地将通用迭代块分块为一系列批量迭代的迭代:
from peewee import chunked
# 一次插入 100 行.
with db.atomic():
for batch in chunked(data, 100):
Person.insert_many(batch).execute()
5、insert_from
使用 SELECT 查询作为源 INSERT 数据。此 API 应用于 INSERT INTO … SELECT FROM … 形式的查询。
insert_from(query, fields)
# query:SELECT查询用作数据源
# fields:要将数据插入的字段,此参数必须要的 **示例:**我们将 Person 表按原结构复制一个 Person2 表出来,以做演示。
data = Person.select(Person.Name, Person.Age, Person.Birthday)
Person2.insert_from(data, ['Name', 'Age', 'Birthday']).execute()
注意: 因为是 INSERT INTO … SELECT FROM … 形式的,所以数据源的列跟要插入的列必须保持一致。
二、删除
1、delete
delete 后加 where 删除指定记录,如果不加 where,则删除全部记录。
Person.delete().where(Person.Name=='王五').execute()
2、delete_instance
删除给定的实例。 语法:
delete_instance(recursive=False, delete_nullable=False)
# 示例:
p = Person.get(Person.Name=='张三')
p.delete_instance()
delete_instance 直接执行删除了,不用调用 execute() 方法。
这两个参数都跟外键有关。我们修改一下测试用的模型。假设有这样两个模型,一个人员,一个部门,人员属于部门。
class Department(Model):
Name = CharField()
class Meta:
database = db
class Person(Model):
Name = CharField()
Age = IntegerField()
Birthday = DateTimeField()
Remarks = CharField(null=True)
Department = ForeignKeyField(Department, null=True) # 这里外键可为空和不可为空是不一样的,下面说明
class Meta:
database = db
- 当
recursive=False时,只删除了【部门】,【人员】没有影响,从 SQL 语句中可以看出。
d = Department.get(1)
d.delete_instance(recursive=False)
# 执行的 SQL 语句
('SELECT "t1"."id", "t1"."Name" FROM "department" AS "t1" WHERE ? LIMIT ? OFFSET ?', [1, 1, 0])
('DELETE FROM "department" WHERE ("department"."id" = ?)', [1])
- 当
recursive=True,并且外键不可为空时,会先删除【部门】下的【人员】,再删除【部门】。
d = Department.get(1)
d.delete_instance(recursive=True)
# 执行的 SQL 语句
('SELECT "t1"."id", "t1"."Name" FROM "department" AS "t1" WHERE ? LIMIT ? OFFSET ?', [1, 1, 0])
('DELETE FROM "person" WHERE ("person"."Department_id" = ?)', [1])
('DELETE FROM "department" WHERE ("department"."id" = ?)', [1])
- 当
recursive=True,并且外键可为空时,先将【人员】的【部门ID(外键字段)】置为了NULL,再删除【部门】。
d = Department.get(1)
d.delete_instance(recursive=True)
# 执行的 SQL 语句
('SELECT "t1"."id", "t1"."Name" FROM "department" AS "t1" WHERE ? LIMIT ? OFFSET ?', [1, 1, 0])
('UPDATE "person" SET "Department_id" = ? WHERE ("person"."Department_id" = ?)', [None, 1])
('DELETE FROM "department" WHERE ("department"."id" = ?)', [1])
delete_nullable仅在recursive=True且外键可为空时有效,和 ③ 一样,当delete_nullable=True时,会删除【人员】,而不是将【人员的部门ID】置为NULL。
d = Department.get(1)
d.delete_instance(recursive=True, delete_nullable=True)
# 执行的 SQL 语句
('SELECT "t1"."id", "t1"."Name" FROM "department" AS "t1" WHERE ? LIMIT ? OFFSET ?', [1, 1, 0])
('DELETE FROM "person" WHERE ("person"."Department_id" = ?)', [1])
('DELETE FROM "department" WHERE ("department"."id" = ?)', [1])
三、修改
1、save
save() 方法可以插入一条记录,一旦模型实例具有主键,任何后续调用 save() 都将导致 UPDATE 而不是另一个 INSERT。模型的主键不会改变。
p = Person(Name='王五', Age=50, Birthday=date(1970, 1, 1))
p.save()
print(p1.id)
p.Remarks = 'abc'
p.save()
# 这个例子,第一次执行的 save 是 INSERT,第二次是 UPDATE。
这里解释一下,
Person这个模型,我并没有指定主键,peewee会自动增加一个名为id的自增列作为主键。在执行第一个save()方法的时候,主键没值,所以执行INSERT,save()方法执行之后,自增列的值就返回并赋给了模型实例,所以第二次调用save()执行的是UPDATE。
如果模型中一开始就用PrimaryKeyField或primary_key指定了主键,那么save执行的永远都是update,所以什么主键不存在则INSERT,存在则UPDATE这种操作根本不存在,只能自己来写判断。
2、update
update 用于批量更新,方法相对简单,以下三种写法都可以
# 方法一
Person.update({Person.Name: '赵六', Person.Remarks: 'abc'}).where(Person.Name=='王五').execute()
# 方法二,字典形式
Person.update({'Name': '赵六', 'Remarks': 'abc'}).where(Person.Name=='张三').execute()
# 方法三
Person.update(Name='赵六', Remarks='abc').where(Person.Name=='李四').execute()
3、原子更新
看这样的一个需求,有一张表,记录博客的访问量,每次有人访问博客的时候,访问量+1。
因为懒得新建模型,我们就以 Person 模型的 Age + 1 来演示。
我们可以这样来写:
for p in Person.select():
p.Age += 1
p.save()
这样当然是可以实现的,但是这不仅速度慢,而且如果多个进程同时更新计数器,它也容易受到竞争条件的影响。
我们可以用 update 方法来实现。
Person.update(Age=Person.Age+1).execute()
四、查询
1、get
Model.get() 方法检索与给定查询匹配的单个实例。 语法:
get(*query, **filters)
# query:查询条件
# filters:Mapping of field-name to value for Django-style filter. 我翻遍网上文章和官方文档都没找到这玩意怎么用!
p1 = Person.get(Name='张三')
p2 = Person.get(Person.Name == '李四')
# 当获取的结果不存在时,报 Model.DoesNotExist 异常。如果有多条记录满足条件,则返回第一条。
2、get_or_none
如果当获取的结果不存在时,不想报错,可以使用 Model.get_or_none() 方法,会返回 None,参数和 get 方法一致。
3、get_by_id
对于主键查找,还可以使用快捷方法 Model.get_by_id()。
Person.get_by_id(1)
4、get_or_create
Peewee 有一个辅助方法来执行“获取/创建”类型的操作: Model.get_or_create() 首先尝试检索匹配的行。如果失败,将创建一个新行。
p, created = Person.get_or_create(Name='赵六', defaults={'Age': 80, 'Birthday': date(1940, 1, 1)})
print(p, created)
# SQL 语句
('SELECT "t1"."id", "t1"."Name", "t1"."Age", "t1"."Birthday", "t1"."Remarks" FROM "person" AS "t1" WHERE ("t1"."Name" = ?) LIMIT ? OFFSET ?', ['赵六', 1, 0])
('BEGIN', None)
('INSERT INTO "person" ("Name", "Age", "Birthday") VALUES (?, ?, ?)', ['赵六', 80, datetime.date(1940, 1, 1)])
参数:
get_or_create 的参数是 **kwargs,其中 defaults 为非查询条件的参数,剩余的为尝试检索匹配的条件,这个看执行时的 SQL 语句就一目了然了。对于“创建或获取”类型逻辑,通常会依赖唯一 约束或主键来防止创建重复对象。但这并不是强制的,比如例子中,我以 Name 为条件,而 Name 并非主键。只是最好不要这样做。
返回值:
get_or_create 方法有两个返回值,第一个是“获取/创建”的模型实例,第二个是是否新创建。
5、select
使用 Model.select() 查询获取多条数据。select 后可以添加 where 条件,如果不加则查询整个表。
ps = Person.select(Person.Name, Person.Age).where(Person.Name == '张三')
select() 返回结果是一个 ModelSelect 对象,该对象可迭代、索引、切片。当查询不到结果时,不报错,返回 None。并且 select() 结果是延时返回的。如果想立即执行,可以调用 execute() 方法。
注意:
where中的条件不支持Name='张三'这种写法,只能是Person.Name == '张三'。
6、获取记录条数 count 方法
Person.select().count()
7、排序 order_by 方法
Person.select().order_by(Person.Age)
# 排序默认是升序排列,也可以用 + 或 asc() 来明确表示是升序排列:
Person.select().order_by(+Person.Age)
Person.select().order_by(Person.Age.asc())
# 用 - 或 desc() 来表示降序:
Person.select().order_by(-Person.Age)
Person.select().order_by(Person.Age.desc())
如要对多个字段进行排序,逗号分隔写就可以了。
五、查询运算符
当查询条件不止一个,需要使用逻辑运算符连接,而 Python 中的 and、or 在 Peewee 中是不支持的,此时我们需要使用 Peewee 封装好的运算符,如下:
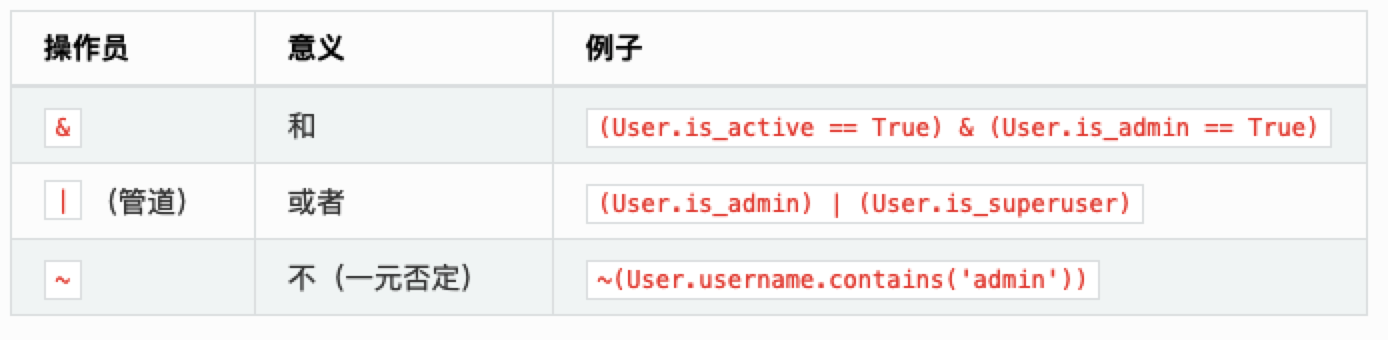
| 逻辑符 | 含义 | 样例 |
|---|---|---|
| & | and | Person.select().where((Person.Name == '张三') & (Person.Age == 30)) |
| | | or | Person.select().where((Person.Name == '张三') \| (Person.Age == 30)) |
| ~ | not | Person.select().where(~Person.Name == '张三') |
特别注意:有多个条件时,每个条件必须用 () 括起来。
当条件全为 and 时,也可以用逗号分隔,get 和 select 中都可以:
Person.get(Person.Name == '张三', Person.Age == 30)
| 比较 | 意义 |
|---|---|
| << | x IN y,其中 y 是列表或查询 |
| >> | x IS y,其中 y 为None / NULL |
| % | x LIKE y,其中 y 可能包含通配符 |
| ** | x LIKE y,其中 y 可能包含通配符 |
| ^ | 异或 |
| ~ | 一元否定(例如,NOT x) |

注意:由于 SQLite 的 LIKE 操作默认情况下不区分大小写,因此 peewee 将使用 SQLite GLOB 操作进行区分大小写的搜索。glob 操作使用星号表示通配符,而不是通常的百分号。如果您正在使用 SQLite 并希望区分大小写的部分字符串匹配,请记住使用星号作为通配符。
解释一下,在 SQLite 中,如果希望 like 的时候区分大小写,可以这么写:
Person.select().where(Person.Remarks % 'a*')
如果不希望区分大小写,这么写:
Person.select().where(Person.Remarks ** 'a%')
六、fn 函数的应用
# 需要导入模块: from peewee import fn [as 别名]
# 或者: from peewee.fn import COUNT [as 别名]
def get_best_users(chan=None, since=datetime.timedelta(days=31), limit=None):
""" Return the number of message by user """
query = [schema.Message.created_at > datetime.datetime.now() - since]
if chan:
query.append(schema.Message.chan == chan)
result = (schema.User
.select(
schema.User.name,
fn.COUNT(schema.Message.id).alias("nb_messages"),
fn.AVG(fn.Length(schema.Message.message)).alias("avg_messages"),
fn.SUM(fn.Length(schema.Message.message)).alias("len_messages"),
)
.join(schema.Message, JOIN.LEFT_OUTER)
.where(*query)
.group_by(schema.User.name)
.order_by(fn.SUM(fn.Length(schema.Message.message)).desc()))
if limit:
result.limit(limit)
return result
# 需要导入模块: from peewee import fn [as 别名]
# 或者: from peewee.fn import COUNT [as 别名]
def user_summary(): # noqa: D103
form = DateRangeForm(request.args)
if not (form.from_date.data and form.to_date.data):
date_range = User.select(
fn.MIN(User.created_at).alias('from_date'),
fn.MAX(User.created_at).alias('to_date')).first()
if date_range:
return redirect(
url_for(
"user_summary",
from_date=date_range.from_date.date().isoformat(),
to_date=date_range.to_date.date().isoformat()))
query = (Organisation.select(Organisation.name,
fn.COUNT(User.id).alias("user_count"),
fn.COUNT(User.orcid).alias("linked_user_count"))
.where(User.created_at.between(form.from_date.data, form.to_date.data)).join(
UserOrg, JOIN.LEFT_OUTER, on=(UserOrg.org_id == Organisation.id)).join(
User, JOIN.LEFT_OUTER, on=(User.id == UserOrg.user_id)).group_by(
Organisation.name))
total_user_count = sum(r.user_count for r in query)
total_linked_user_count = sum(r.linked_user_count for r in query)
return render_template(
"user_summary.html",
form=form,
query=query,
total_user_count=total_user_count,
total_linked_user_count=total_linked_user_count)













